

Webスクレイピングとは
WebページからHTMLを取得し、情報の抽出や整形、解析を行うこと
スクレイピング・・・WebページのHTMLから必要な情報を取得、整形、解析すること
クローリング・・・Webページのリンクをたどり、Webページの情報を収集すること
- テキストや画像を自動で取得
- 欲しい情報をまとめて取得
- 取得したデータの整形
- 自動ログイン
- テキストや画像データを取得
- データの整形
Webスクレイピング活用事例
- マーケティング
- サービス開発
Webスクレイピング用ライブラリ(Python)
- Selenium
- BeautifulSoup
- requests
- PyQuery
- scrapy
Seleniumクイックリファレンス
Seleniumで何ができるかは、Selenium APIを参照してみてください。
大項目として以下のアクションが整理されています。
- ウインドウを操作する
- ウインドウ情報を取得する
- 要素を取得する(要素取得について)
- 要素から情報を取得する
- 要素の状態を判定する
- 要素を操作する
- 複数同時操作をする(アクションについて)
- 待ち時間を設定する
- 条件を指定して待機する(条件を指定して待機について)
- I/O操作をする(一時ファイルシステムについて)
- ブラウザ環境情報を取得する(Capabilitiesについて)
- ブラウザの環境設定をする
- マシン情報を取得する
- イベントに対して処理を実施する(イベント処理について)
Selenium+Jupyter Noteのインストール
ここではSeleniumとJupyter Notebookをインストールし、起動するか確認します。
- seleniumインストール
- 画像処理ライブラリpillowをインストール
- Jupyter Notebookを起動
- Jupyter Notebookを停止
- 自動補完Extensionの追加
macのTerminalを起動して以下のコマンドを実行してインストール
pip3 install selenium同様にpip3コマンドを実行してインストール
pip3 install pillowJupyter Notebookは、ブラウザ上で動作するプログラムの対話型実行環境です。
Juptyter Notebookによる開発用フォルダを適宜作成して、フォルダに移動します。
(今回はpythonフォルダとしました)
jupyter notebookJuptyter Notebookによる開発用フォルダを適宜作成して、フォルダに移動します。
(今回はpythonフォルダとしました)
正常に起動するとコマンドを実行したフォルダの初期画面が表示されます。
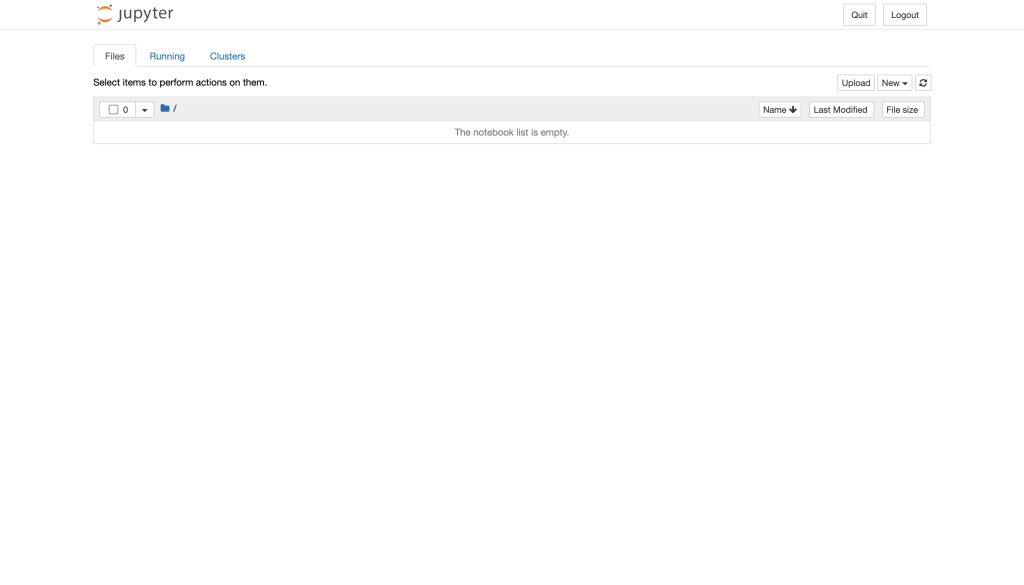
Webブラウザの”Quit”から停止させることが可能です。一度停止させて、プログラムに便利な自動保管のExtensionを追加しましょう。
macのTerminalを起動して以下のコマンドを実行してExtensionをインストール
# ライブラリをインストール
pip install jupyter-contrib-nbextensions
pip install jupyter-nbextensions-configurator
# 拡張機能を有効化する
jupyter contrib nbextension install
jupyter nbextensions_configurator enable再度Jupyter Notebookを起動します。
jupyter notebook“Nbextensions”のタブが追加されているので、”disable”のチェックボックを外し、”Hinterland”にチェックを入れて”Enable”に設定します。
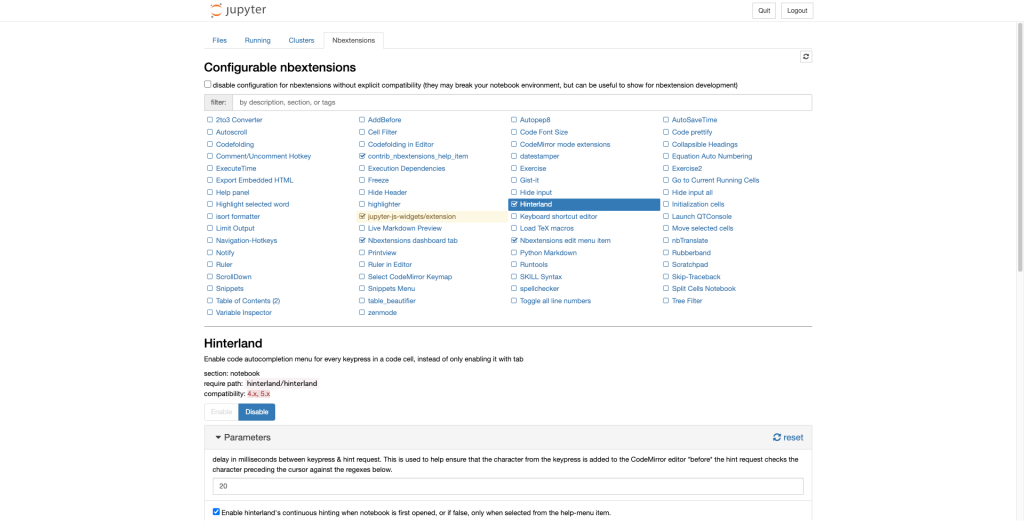
コードの自動補完機能が拡張されていればOKです。
自動ログイン
ここではJupyter Notebookを用いて、Wordpressに自動ログインするプログラムを作成してみます。
- 環境構築
- 自動ログイン
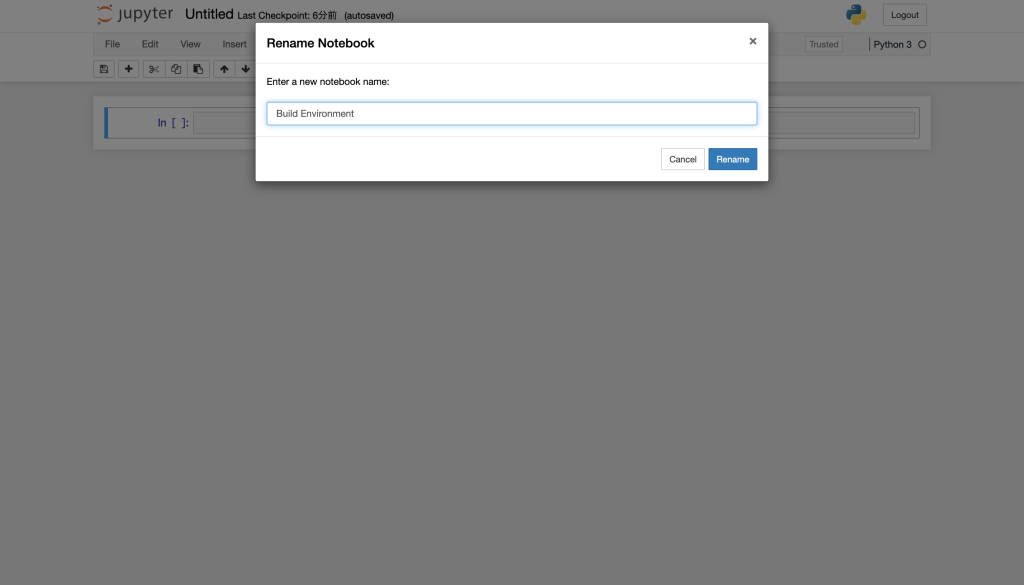
「New」→「python3」から新規Notebookを作成します。
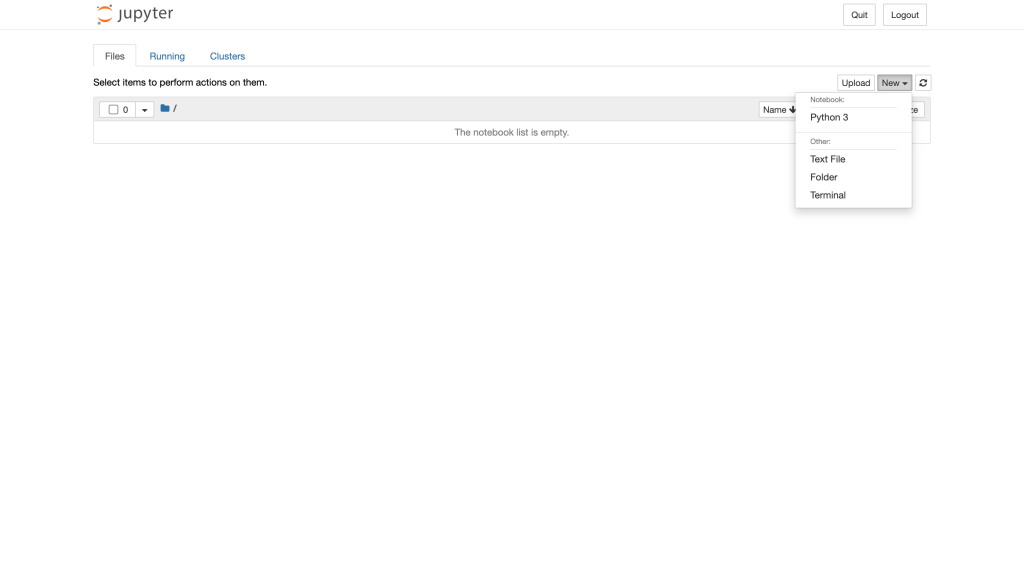
Notebookの名前を適当な名前に変更します。今回は、「Build Enviroment」に変更します。
python3からfirefoxが呼び出せるか確認します。以下のコマンドを実行してみてください。
Jupyter Notebookは対話型の実行環境ですので、一行ずつコマンドが実行されていきます。
from selenium import webdriver
browser = webdriver.Firefox()Firefoxが起動しない場合があります。その場合は、MacのTerminalから以下のgeckodriverをインストールしてください。Firefoxが無事起動すれば成功です。
brew install geckodriver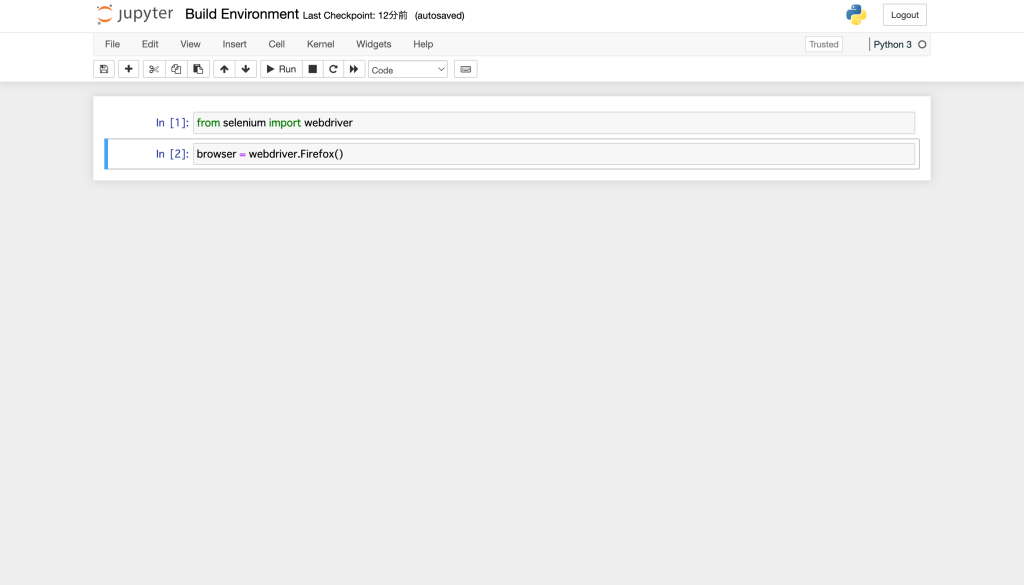
python3からchromeが呼び出せるか確認します。以下のコマンドを実行してみてください。
browser = webdriver.Chrome()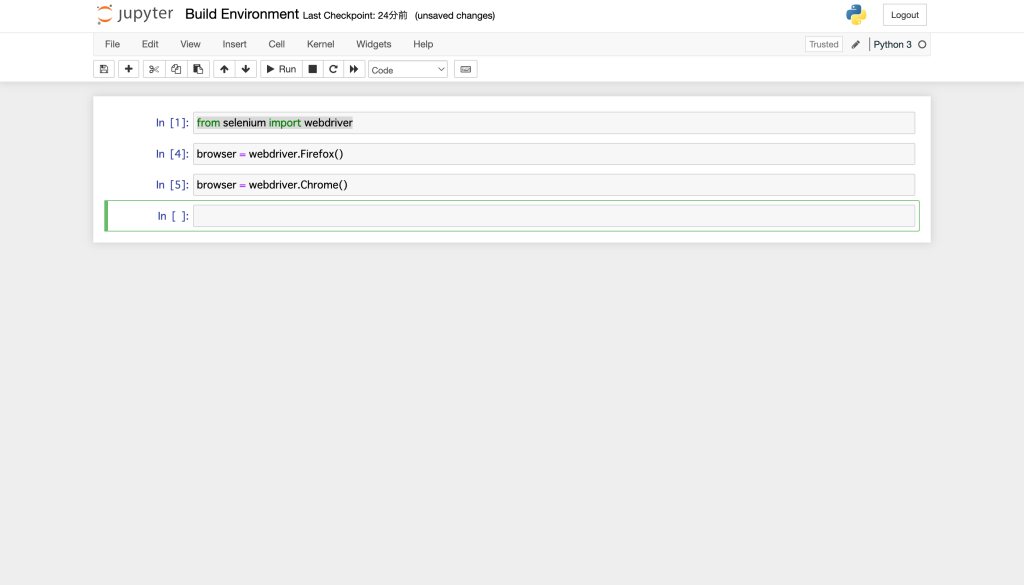
最後に、python3からPILが呼び出せるか確認します。以下のコマンドを実行してみてください。
from PIL import Imagepyhonでは大文字と小文字が明確に区別されるため、Imageの部分をimageとするとエラーとなるので、注意下さい。
from PIL import image # エラーメッセージ
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-8-7892611e7a30> in <module>
----> 1 from PIL import image
ImportError: cannot import name 'image' from 'PIL' (/Users/mkono/Library/Python/3.9/lib/python/site-packages/PIL/__init__.py)ブラウザは、以下のコマンドから閉じることが可能です。ちなみにbrowser.getで複数呼び出した状態では、最後に呼び出したブラウザ画面に対してその後のコマンドが実行され、複数ブラウザに対して同時にはコマンド実行されません。
browser.quit()Jupyter NotebookからChromeでWebページを開き、ログイン画面にユーザー名とパスワードを自動入力してログインできるか確認します。
Selenium v4.3以降からコマンド実行の記述が異なってしまったため、MacのTerminalから現在のSeleniumのバージョンを確認してください。ここではv4.3以降として記載しています。(私の環境では、v4.7.2でした)
pip list | gerp selenium
selenium 4.7.2以下のように、Selenium v4.3以前の記述方式でv.4.3以降のSelenium環境で実行すると、’WebDriver’には’find_element_by_id’の属性はありませんと注意されます。
#要素を指定
elem_username=browser.find_element_by_id('username')
---------------------------------------------------------------------------
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-18-0f0224271bfa> in <module>
1 #要素を指定
----> 2 elem_username=browser.find_element_by_id('username')
AttributeError: 'WebDriver' object has no attribute 'find_element_by_id'それでは、自動ログインのコードを作成していきます。一度Jupyter Notebookに記載した行を全て消しましょう。
[Ctrl+A]で全て選択された状態で、[x]を押すと全行カットされます。
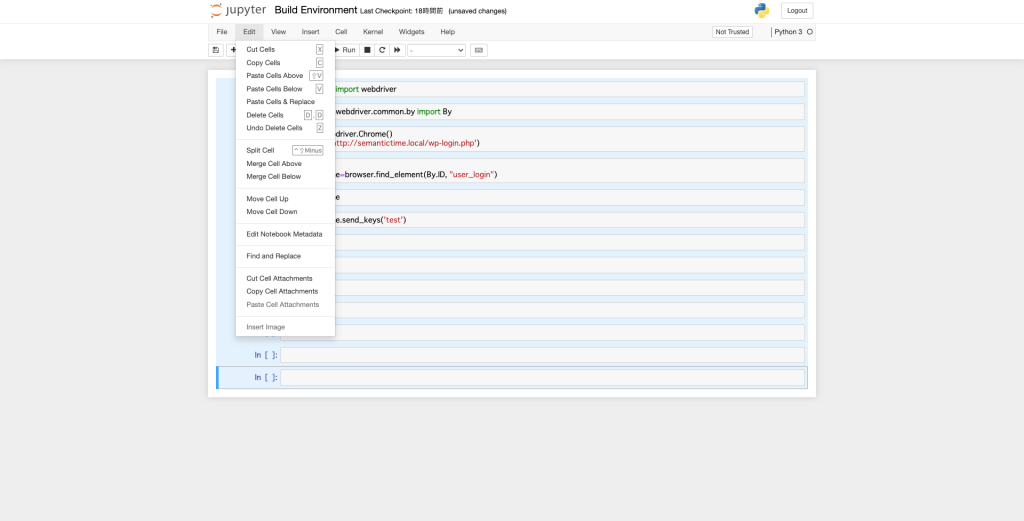
v4.3以降の手順では、webdriverの’By’をimportする必要がありますので、最初に宣言します。
今回はChromeを用いてローカルのWordPressのサイトに検証できるか検証してみました
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('http://semantictime.net/wp-login.php')
elem_username=browser.find_element(By.ID, 'user_login')
elem_username
elem_username.send_keys('test')
elem_password=browser.find_element(By.ID, 'user_pass')
elem_password
elem_password.send_keys('MglTSO5gbOsm')
elem_login_btn=browser.find_element(By.ID, 'wp-submit')
elem_login_btn
elem_login_btn.click()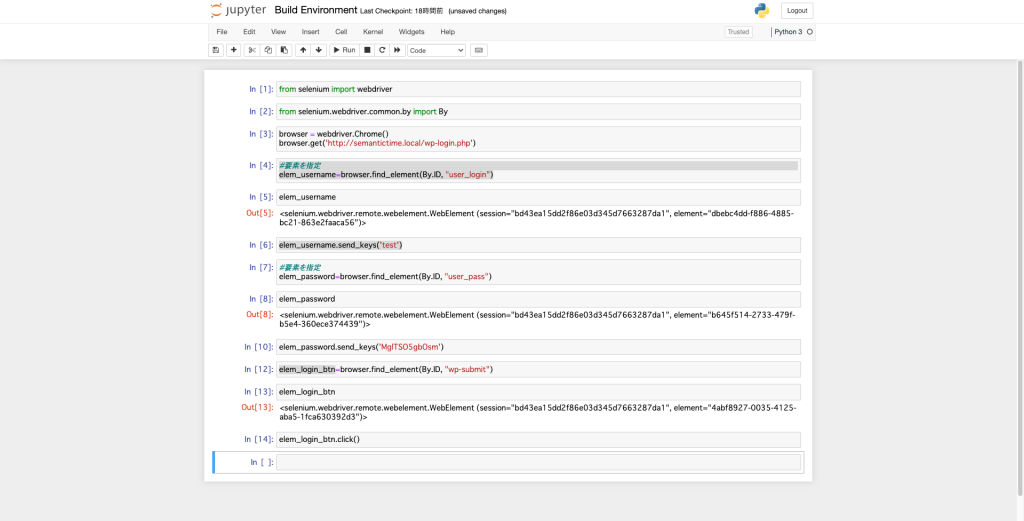
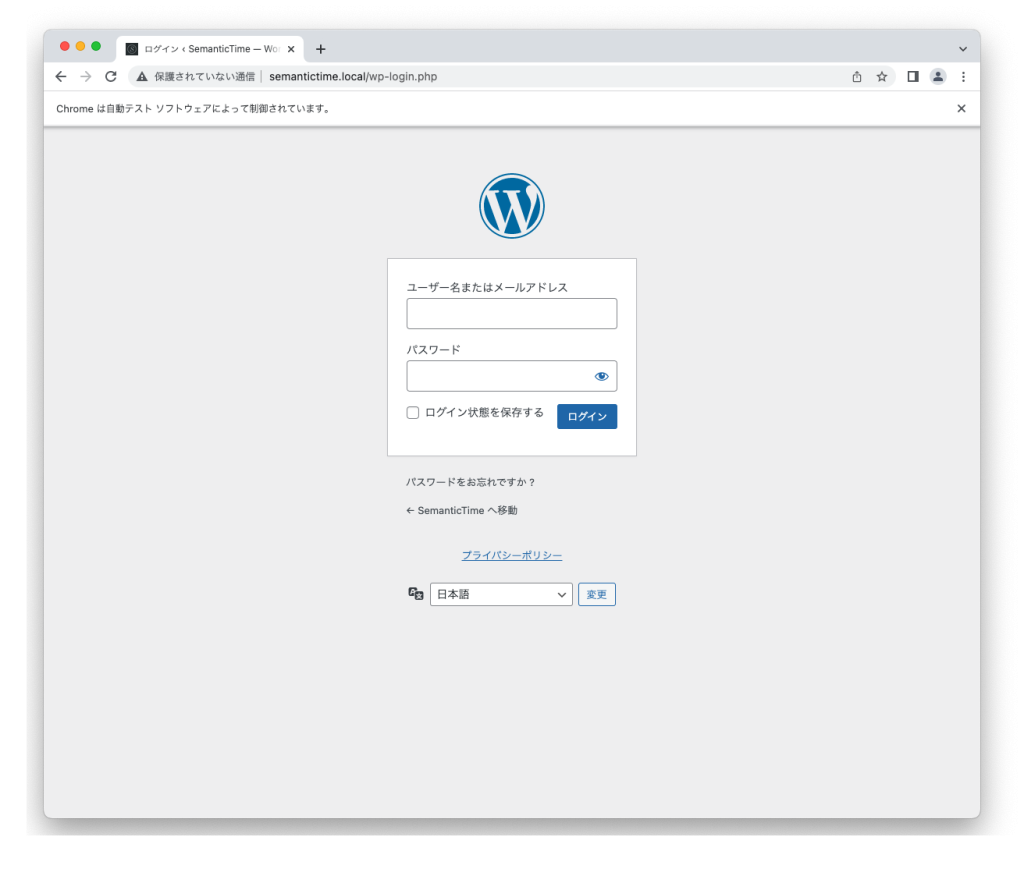
brwoser.find_element(By.ID, ‘user_login’)というコマンドを実行していますが、これはHTMLの中でID=’User_login’の要素を指定するという意味です。
ユーザー名を入力する要素を特定するために、Chromeの画面でF12を押してデベロッパーツールを起動、矢印マークのボタンを押し、ユーザー名の入力エリアを選択してみてください。
以下のように、オレンジでうまく選択できていれば、対象のHTMLコードがハイライトされ、id=’user_login’という部分を検索できます。
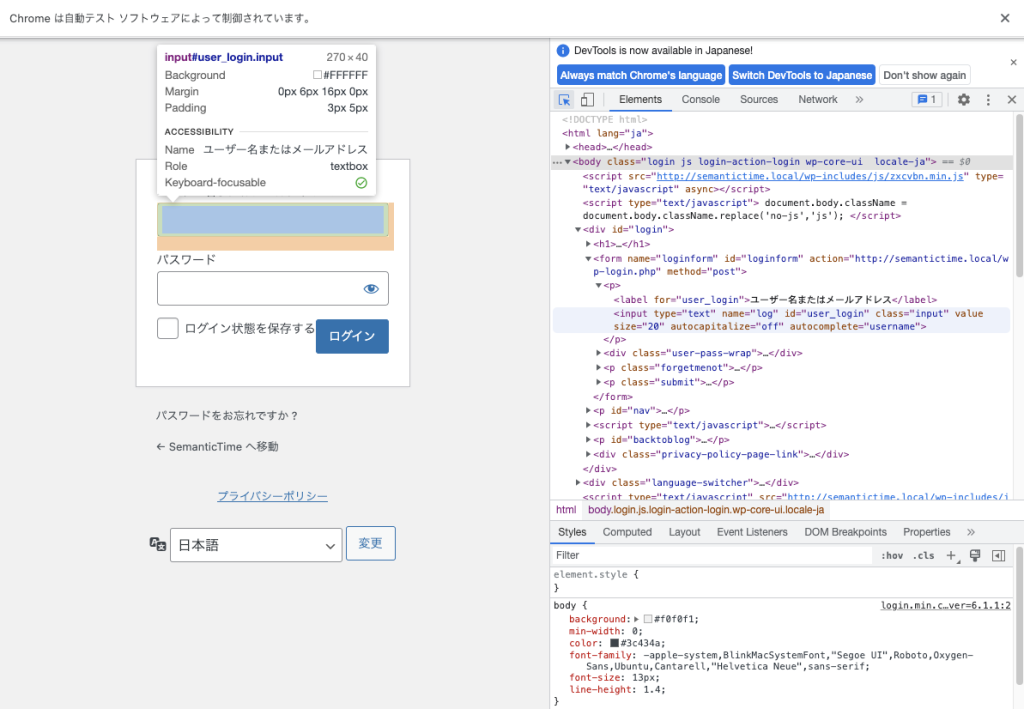
正常に要素が抽出されていれば、’send_keys’コマンドにより入力キーを送信できます。
elem_username.send_keys(‘test’)
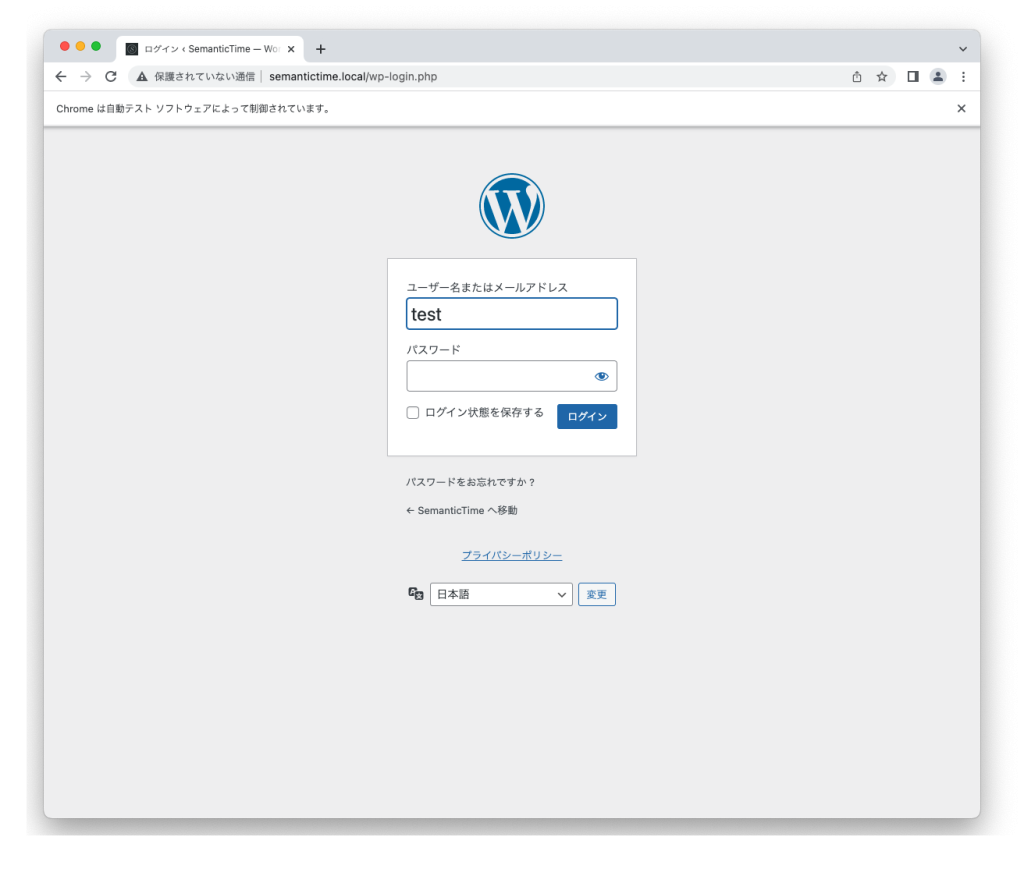
同様にパスワードエリア、ログインボタンについてもIDから要素を抽出してみてください。
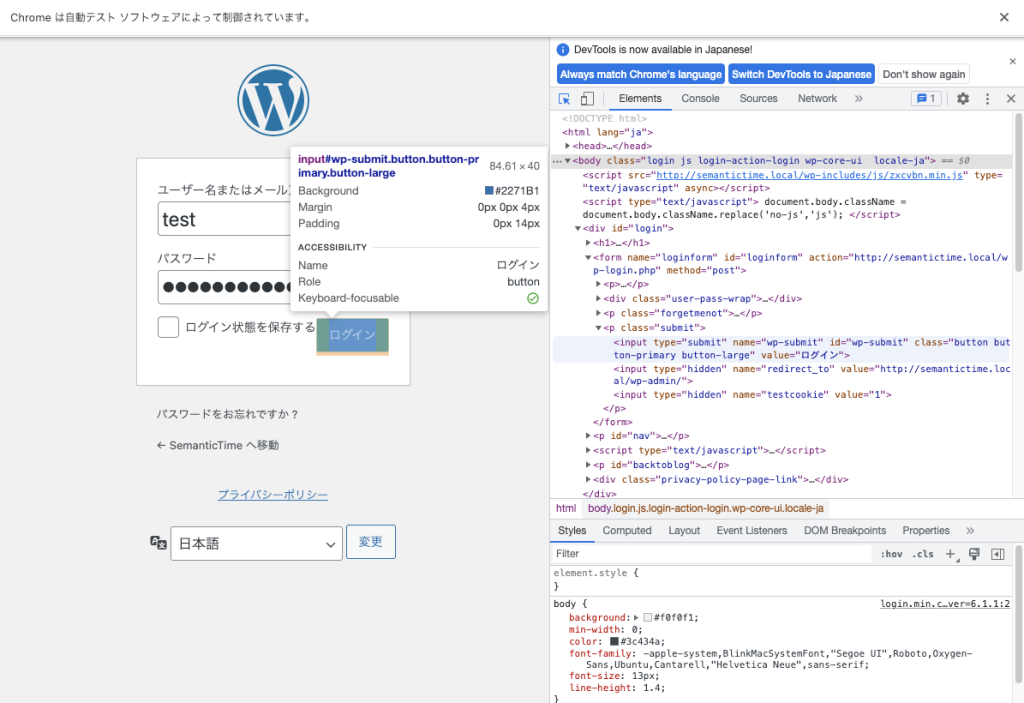
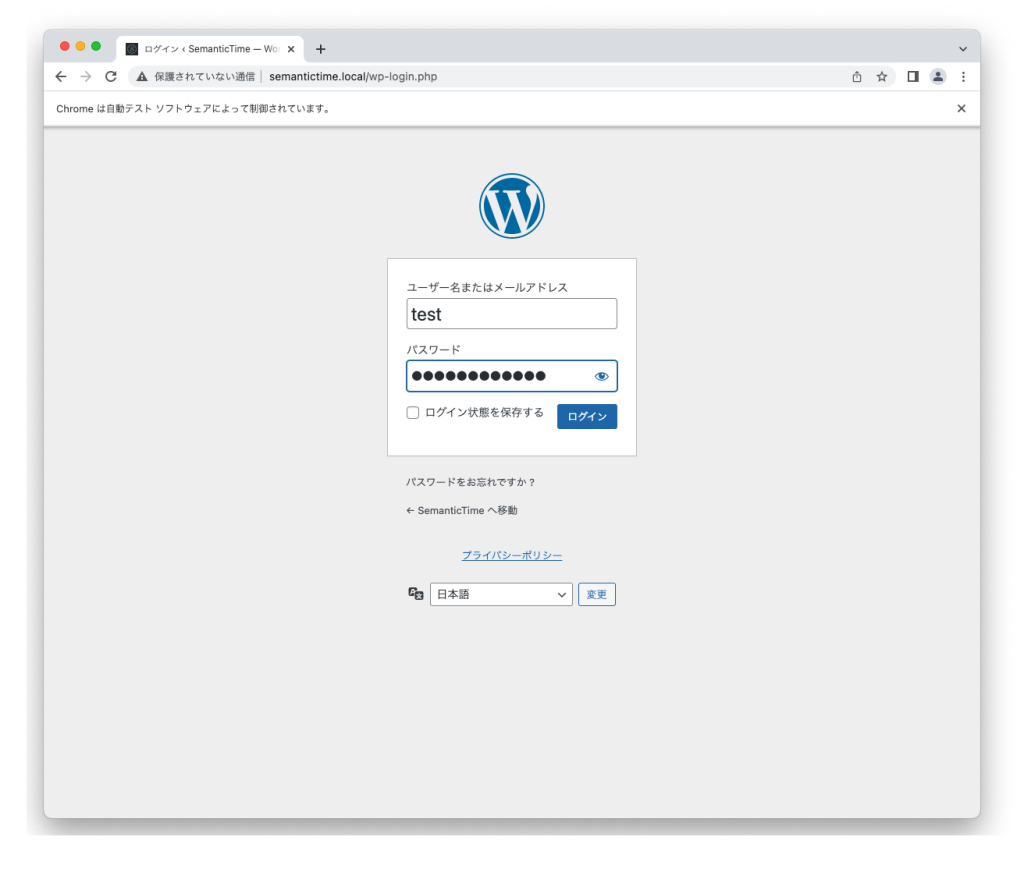
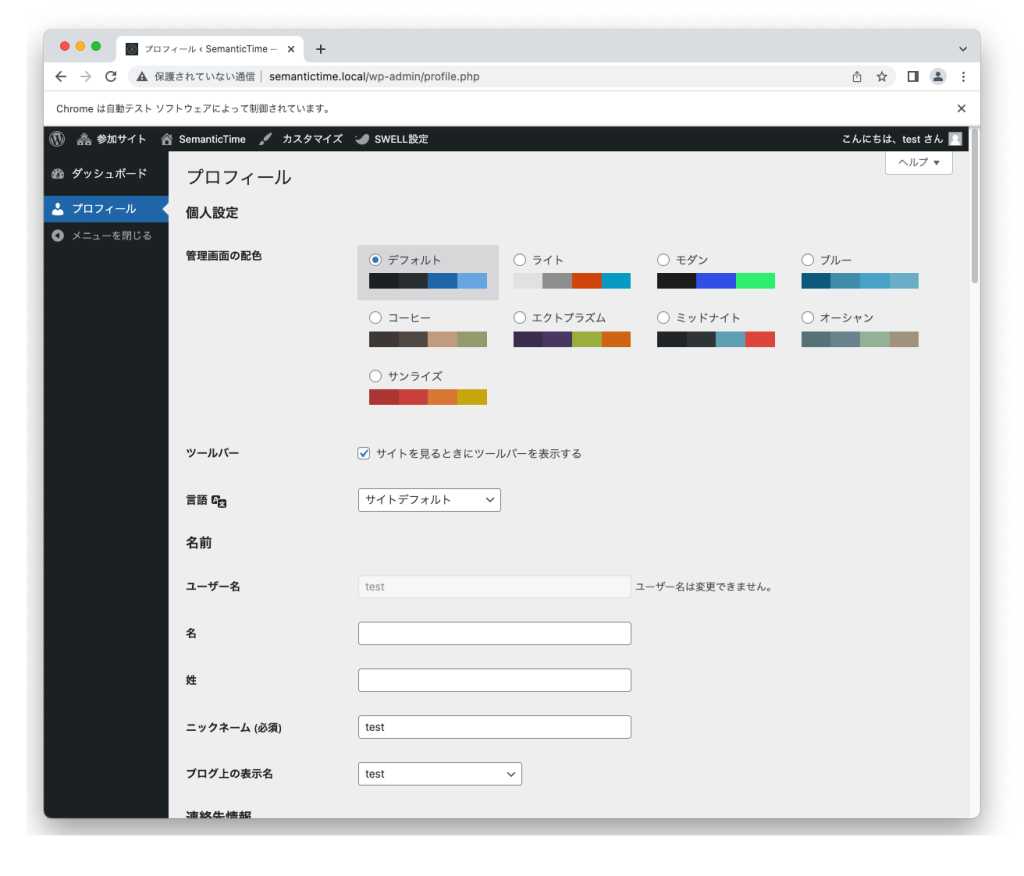
‘btn.click()’コマンドにより、ボタンがクリックされて、無事自動ログインができました。
下記では、Wordpressのユーザープロファイル画面に遷移しました。
テキスト抽出 & CSVファイル出力
ここではWordpressから構造化されたテキストを抽出するプログラムを作成してみます。
- テキスト抽出
- CSVファイル出力
「New」→「python3」から新規Notebookを作成します。
Notebookの名前を適当な名前に変更します。今回は、「Extract Textdata」に変更します。
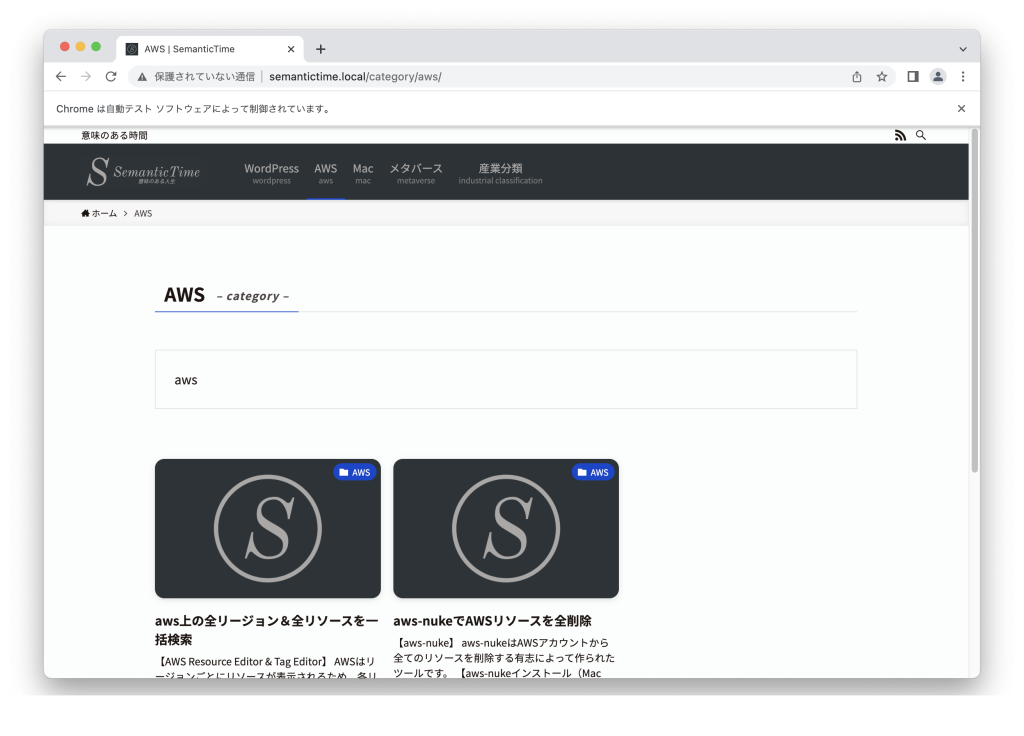
今回はWordpressのawsカテゴリの2記事のタイトル名を抽出してみます。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('http://semantictime.net/category/aws')
elem_newarticle = browser.find_element(By.CLASS_NAME, 'p-postList__title')
elem_newarticle
elem_newarticle.text
elem_newarticles = browser.find_elements(By.CLASS_NAME, 'p-postList__title')
elem_newarticles
type(elem_newarticles)
for elem in elem_newarticles: print(elem.text)
単数の要素を取得する際は、find_elementコマンドを使いましたが、複数要素を抽出したい場合は、find_elementsコマンドを利用します。
# 単数の要素を取得
elem_newarticle = browser.find_element(By.CLASS_NAME, 'p-postList__title')
# 複数の要素を取得
elem_newarticles = browser.find_elements(By.CLASS_NAME, 'p-postList__title')複数要素を取得した構造となっているため、list型となっています。
type(elem_newarticles)
list中身の要素を全て出力するには、以下のようにfor分を用いることで、全ての要素を出力させることが可能です。
for elem in elem_newarticles: print(elem.text)
aws上の全リージョン&全リソースを一括検索
aws-nukeでAWSリソースを全削除上記抽出した要素をPandasを用いて整形して、CSVファイルに出力します。
title = []
for elem in elem_newarticles:
title.append(elem.text)
title
import pandas as pd
# 空のDataFrameを定義
df = pd.DataFrame()
df['タイトル'] = title
df
df.to_csv("article_title.csv")
df.to_csv("article_title_noindex.csv",index=False)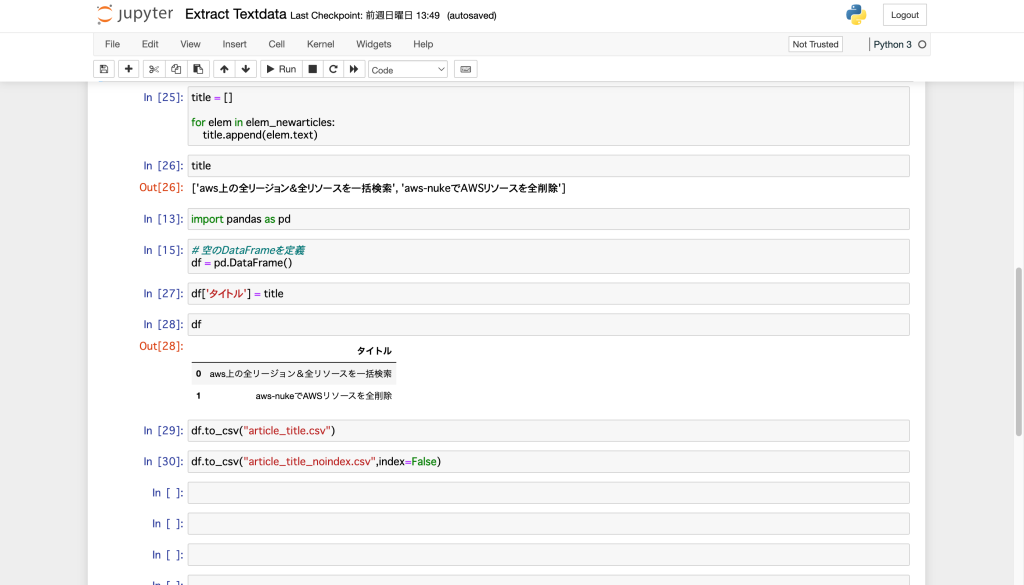
PandasのDataFrameにデータを受け渡すために、一度titleという配列に要素名のデータを保管します。
“title”を出力すると、正常にデータが配列に保管されていることが確認できます。
title = []
for elem in elem_newarticles:
title.append(elem.text)
title
['aws上の全リージョン&全リソースを一括検索', 'aws-nukeでAWSリソースを全削除']Pandasは、データ解析を支援する機能を提供するライブラリです。
データフレームは2次元のラベル付きのデータ構造で、Pandasでは最も多く使われるデータ型です。
ここでは、”タイトル”という項目を設定して、抽出した要素を出力するように記述しています。
import pandas as pd
# 空のDataFrameを定義
df = pd.DataFrame()
df['タイトル'] = title
df
タイトル
0 aws上の全リージョン&全リソースを一括検索
1 aws-nukeでAWSリソースを全削除
df.to_csv("article_title.csv") #インデックスあり
df.to_csv("article_title_noindex.csv",index=False) #インデックスなしJupyter Notebookを起動したフォルダに、「article_title.csv」と「article_tile_noindex.csv」ファイルが作成されて、要素が出力されていれば成功です。
ランキング抽出
ここでは価格.comから構造化されたテキストを抽出するプログラムを作成してみます。
- 構造化データのテキスト抽出
- CSVファイル出力
「New」→「python3」から新規Notebookを作成します。
Notebookの名前を適当な名前に変更します。今回は、「Extract Structuredata」に変更します。
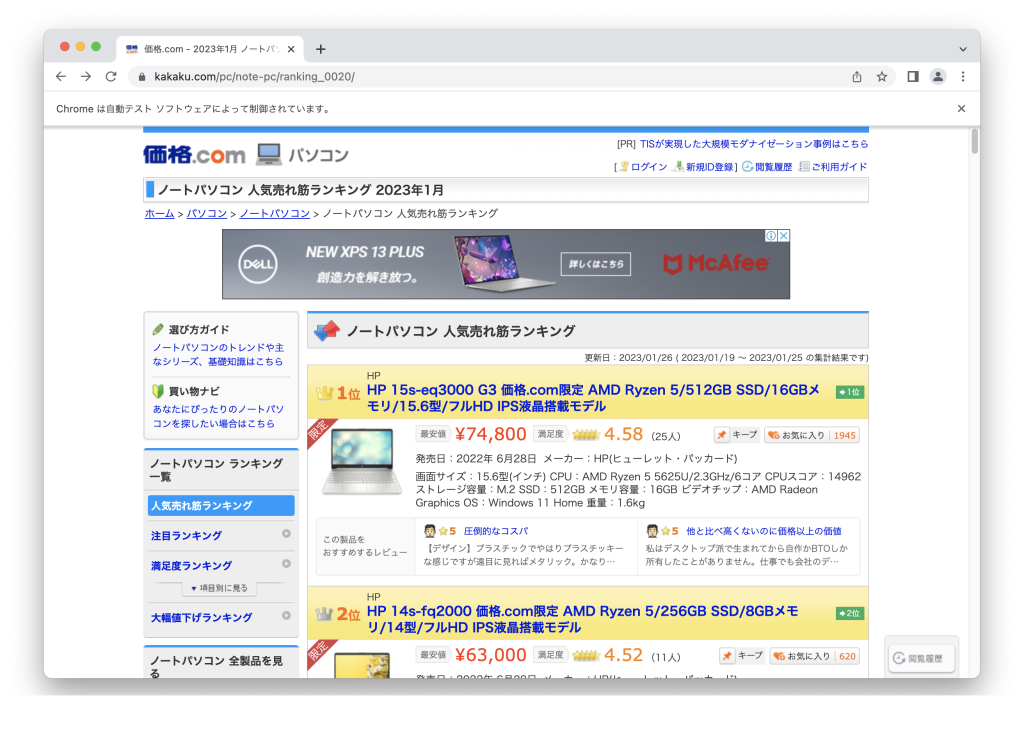
今回は価格.comのノートパソコン 人気売れ筋ランキングの情報を抽出してみます。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://kakaku.com/pc/note-pc/ranking_0020/')
elem_ranks = browser.find_elements(By.CLASS_NAME, 'rkgBoxNum')
ranks = []
for elem in elem_ranks:
print(elem.text)
ranks.append(elem.text)
ranks
elem_prices = browser.find_elements(By.CLASS_NAME, 'price')
prices = []
for elem in elem_prices:
print(elem.text)
prices.append(elem.text)
prices
elem_pointrank = browser.find_elements(By.CLASS_NAME, 'point rank4h')単数の要素を取得する際は、find_elementコマンドを使いましたが、複数要素を抽出したい場合は、find_elementsコマンドを利用します。
仕様変更に伴い、Seleniumで”by_class_name”でスペースが入った要素が取得できずエラーになりました。そのような場合は、”driver.find_element_by_css_selector”メソッドを用いて代替するのが一般的です。
# 単数の要素を取得
elem_newarticle = browser.find_element(By.CLASS_NAME, "p-postList__title")
# 複数の要素を取得
elem_newarticles = browser.find_elements(By.CLASS_NAME, "p-postList__title")複数要素を取得した構造となっているため、list型となっています。
type(elem_newarticles)
list中身の要素を全て出力するには、以下のようにfor分を用いることで、全ての要素を出力させることが可能です。
for elem in elem_newarticles: print(elem.text)
aws上の全リージョン&全リソースを一括検索
aws-nukeでAWSリソースを全削除上記抽出した要素をPandasを用いて整形して、CSVファイルに出力します。
title = []
for elem in elem_newarticles:
title.append(elem.text)
title
import pandas as pd
# 空のDataFrameを定義
df = pd.DataFrame()
df['タイトル'] = title
df
df.to_csv("article_title.csv")
df.to_csv("article_title_noindex.csv",index=False)PandasのDataFrameにデータを受け渡すために、一度titleという配列に要素名のデータを保管します。
“title”を出力すると、正常にデータが配列に保管されていることが確認できます。
title = []
for elem in elem_newarticles:
title.append(elem.text)
title
['aws上の全リージョン&全リソースを一括検索', 'aws-nukeでAWSリソースを全削除']Pandasは、データ解析を支援する機能を提供するライブラリです。
データフレームは2次元のラベル付きのデータ構造で、Pandasでは最も多く使われるデータ型です。
ここでは、”タイトル”という項目を設定して、抽出した要素を出力するように記述しています。
import pandas as pd
# 空のDataFrameを定義
df = pd.DataFrame()
df['タイトル'] = title
df
タイトル
0 aws上の全リージョン&全リソースを一括検索
1 aws-nukeでAWSリソースを全削除
df.to_csv("article_title.csv") #インデックスあり
df.to_csv("article_title_noindex.csv",index=False) #インデックスなしJupyter Notebookを起動したフォルダに、「article_title.csv」と「article_tile_noindex.csv」ファイルが作成されて、要素が出力されていれば成功です。